Synthetic Control Method
[1]:
import os
import normet as nm
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
[2]:
df=pd.read_csv('data/AQ_Weekly.csv',parse_dates=['date'])
[3]:
df=df.query(f"date>='2015-05-01'").query(f"date<'2016-04-30'")
[4]:
control_pool=["Dongguan", "Zhongshan" , "Foshan", "Beihai"
, "Nanning","Nanchang" , "Xiamen", "Taizhou"
, "Ningbo","Guangzhou" , "Huizhou", "Hangzhou"
, "Liuzhou", "Shantou", "Jiangmen", "Heyuan", "Quanzhou","Haikou" , "Shenzhen", "Wenzhou", "Huzhou"
, "Zhuhai", "Fuzhou", "Shaoxing", "Zhaoqing","Zhoushan"
, "Quzhou", "Jinhua", "Shaoguan" , "Sanya"
, "Jieyang" , "Meizhou", "Shanwei"
, "Zhanjiang" , "Chaozhou", "Maoming" , "Yangjiang"]
[5]:
df=df[df['ID'].isin(control_pool+["2+26 cities"])]
[6]:
df.head()
[6]:
| date | ID | CO | COwn | NO2 | NO2wn | O3 | O3_8h | O3_8hwn | O3wn | Ox | Oxwn | PM10 | PM10wn | PM2.5 | PM2.5wn | SO2 | SO2wn | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 552 | 2015-05-03 | 2+26 cities | 1.277812 | 1.328918 | 38.484623 | 45.068304 | 83.690318 | 133.060175 | 90.980089 | 65.825884 | 60.984249 | 54.415501 | 134.523758 | 139.447383 | 82.221006 | 73.876656 | 32.971551 | 36.822724 |
| 560 | 2015-05-10 | 2+26 cities | 1.113243 | 1.298979 | 35.289414 | 44.352582 | 70.075957 | 103.363985 | 90.875789 | 66.100641 | 52.659234 | 54.337364 | 111.771975 | 134.412595 | 58.313419 | 69.386309 | 27.898696 | 35.284317 |
| 568 | 2015-05-17 | 2+26 cities | 0.996762 | 1.274902 | 35.810778 | 43.981644 | 83.598553 | 125.082867 | 91.245896 | 66.418891 | 59.588514 | 54.389203 | 117.075504 | 129.474025 | 52.802738 | 67.146002 | 29.642007 | 34.742172 |
| 576 | 2015-05-24 | 2+26 cities | 1.031094 | 1.267058 | 39.838150 | 43.398110 | 96.838000 | 149.709652 | 92.792728 | 66.695864 | 68.180477 | 54.529002 | 117.650986 | 121.537391 | 61.278043 | 65.876502 | 34.972942 | 34.482513 |
| 584 | 2015-05-31 | 2+26 cities | 1.297053 | 1.285556 | 37.988483 | 43.548340 | 109.770206 | 165.029314 | 92.427553 | 66.419975 | 73.600167 | 54.475052 | 143.115653 | 126.681810 | 88.963408 | 67.239277 | 33.903061 | 34.490734 |
[7]:
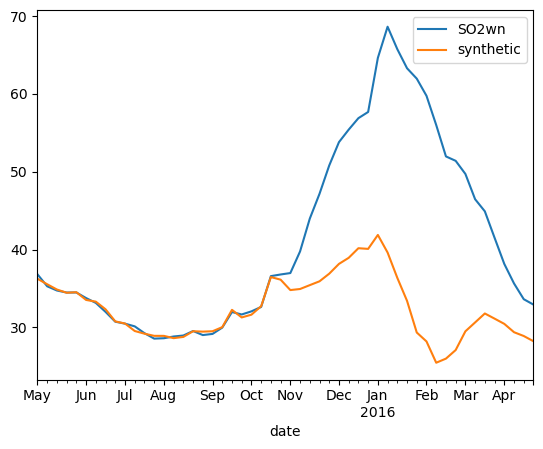
xx=nm.scm(df,'SO2wn','ID',"2+26 cities",control_pool,'2015-10-23')
[8]:
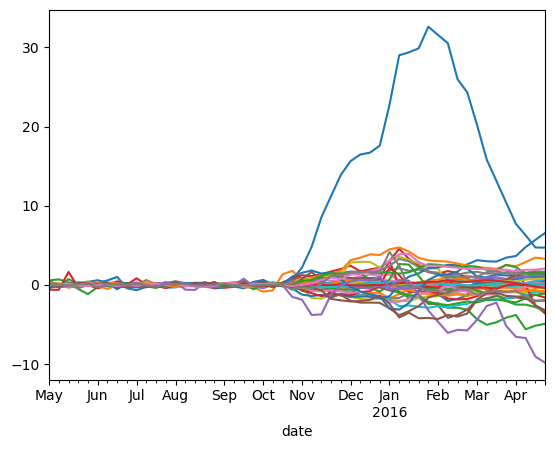
xy=nm.scm_all(df,'SO2wn','ID',control_pool,'2015-10-23')
[9]:
xx[['SO2wn','synthetic']].plot()
[9]:
<Axes: xlabel='date'>
[10]:
fig,ax=plt.subplots()
for i,city in enumerate(list(xy['ID'].unique())):
xy[xy['ID']==city]['effects'].plot(ax=ax)
[11]:
mlscdata1=nm.mlsc(df,'SO2wn','ID',"2+26 cities",control_pool,'2015-10-23',automl_pkg='flaml')
2024-09-24 21:10:59 : Training AutoML...
2024-09-24 21:12:29 : Best model is lgbm with best model parameters of {'n_estimators': 4, 'num_leaves': 6, 'min_child_samples': 2, 'learning_rate': 0.7148544310430003, 'log_max_bin': 4, 'colsample_bytree': 0.1939065104493952, 'reg_alpha': 0.01427319308925257, 'reg_lambda': 0.009361671309532844}
[12]:
mlscdata2=nm.mlsc(df,'SO2wn','ID',"2+26 cities",control_pool,'2015-10-23',automl_pkg='h2o')
H2O is not running. Starting H2O...
Checking whether there is an H2O instance running at http://localhost:54321. connected.
| H2O_cluster_uptime: | 8 hours 50 mins |
| H2O_cluster_timezone: | Europe/London |
| H2O_data_parsing_timezone: | UTC |
| H2O_cluster_version: | 3.46.0.5 |
| H2O_cluster_version_age: | 26 days |
| H2O_cluster_name: | H2O_from_python_n94921cs_5qrqdn |
| H2O_cluster_total_nodes: | 1 |
| H2O_cluster_free_memory: | 6.829 Gb |
| H2O_cluster_total_cores: | 8 |
| H2O_cluster_allowed_cores: | 1 |
| H2O_cluster_status: | locked, healthy |
| H2O_connection_url: | http://localhost:54321 |
| H2O_connection_proxy: | {"http": null, "https": null} |
| H2O_internal_security: | False |
| Python_version: | 3.12.2 final |
2024-09-24 21:12:29: Training AutoML...
21:12:29.854: _min_rows param, The dataset size is too small to split for min_rows=100.0: must have at least 200.0 (weighted) rows, but have only 25.0.
2024-09-24 21:12:43: Best model obtained! - GBM_grid_1_AutoML_84_20240924_211229_model_1
[13]:
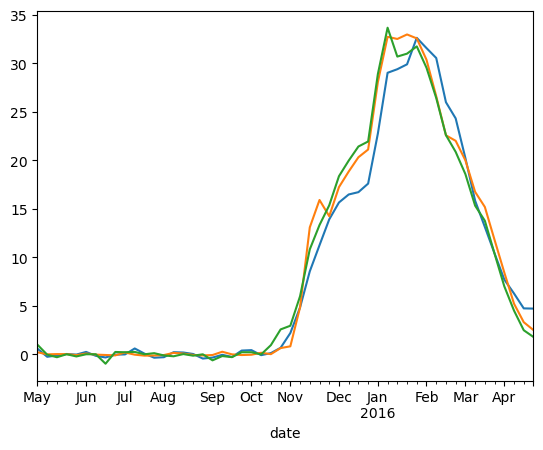
fig,ax=plt.subplots()
xx['effects'].plot(ax=ax)
mlscdata1['effects'].plot(ax=ax)
mlscdata2['effects'].plot(ax=ax)
[13]:
<Axes: xlabel='date'>
[14]:
model_config = {
'time_budget': 10, # Total running time in seconds
'metric': 'r2', # Primary metric for regression, 'mae', 'mse', 'r2', 'mape',...
'estimator_list': ["lgbm"], # List of ML learners: "lgbm", "rf", "xgboost", "extra_tree", "xgb_limitdepth"
}
mlscdataall_1=nm.mlsc_all(df,'SO2wn','ID',control_pool,'2015-10-23',automl_pkg='flaml', model_config=model_config)
2024-09-24 21:12:44 : Training AutoML...
2024-09-24 21:12:54 : Best model is lgbm with best model parameters of {'n_estimators': 12, 'num_leaves': 5, 'min_child_samples': 2, 'learning_rate': 1.0, 'log_max_bin': 10, 'colsample_bytree': 0.930479165045027, 'reg_alpha': 0.00942574688215323, 'reg_lambda': 13.299403187619442}
2024-09-24 21:12:54 : Training AutoML...
2024-09-24 21:13:04 : Best model is lgbm with best model parameters of {'n_estimators': 6, 'num_leaves': 4, 'min_child_samples': 9, 'learning_rate': 0.2921597058142577, 'log_max_bin': 5, 'colsample_bytree': 0.783599369600188, 'reg_alpha': 0.0009765625, 'reg_lambda': 0.46338749432065923}
2024-09-24 21:13:04 : Training AutoML...
2024-09-24 21:13:14 : Best model is lgbm with best model parameters of {'n_estimators': 6, 'num_leaves': 5, 'min_child_samples': 3, 'learning_rate': 1.0, 'log_max_bin': 7, 'colsample_bytree': 0.9503055774263902, 'reg_alpha': 0.489191843809506, 'reg_lambda': 1.6501523530499025}
2024-09-24 21:13:14 : Training AutoML...
2024-09-24 21:13:24 : Best model is lgbm with best model parameters of {'n_estimators': 6, 'num_leaves': 5, 'min_child_samples': 2, 'learning_rate': 0.41160801397294977, 'log_max_bin': 8, 'colsample_bytree': 0.9169378900537527, 'reg_alpha': 0.0009765625, 'reg_lambda': 0.0831188539939598}
2024-09-24 21:13:24 : Training AutoML...
2024-09-24 21:13:34 : Best model is lgbm with best model parameters of {'n_estimators': 11, 'num_leaves': 6, 'min_child_samples': 2, 'learning_rate': 0.32797464931090686, 'log_max_bin': 10, 'colsample_bytree': 0.7801126486250443, 'reg_alpha': 0.00783683094772429, 'reg_lambda': 0.0009765625}
2024-09-24 21:13:34 : Training AutoML...
2024-09-24 21:13:44 : Best model is lgbm with best model parameters of {'n_estimators': 8, 'num_leaves': 6, 'min_child_samples': 3, 'learning_rate': 0.1557307908422462, 'log_max_bin': 7, 'colsample_bytree': 0.42586054853597943, 'reg_alpha': 0.012954181982556719, 'reg_lambda': 0.6977141807080524}
2024-09-24 21:13:44 : Training AutoML...
2024-09-24 21:13:54 : Best model is lgbm with best model parameters of {'n_estimators': 6, 'num_leaves': 4, 'min_child_samples': 2, 'learning_rate': 0.7522841109457985, 'log_max_bin': 8, 'colsample_bytree': 0.7553536260637193, 'reg_alpha': 0.12884573478098568, 'reg_lambda': 0.34337932545067434}
2024-09-24 21:13:54 : Training AutoML...
2024-09-24 21:14:04 : Best model is lgbm with best model parameters of {'n_estimators': 11, 'num_leaves': 5, 'min_child_samples': 2, 'learning_rate': 0.7559672399847629, 'log_max_bin': 8, 'colsample_bytree': 0.5980451945038232, 'reg_alpha': 0.00118162844757217, 'reg_lambda': 0.050562689919296896}
2024-09-24 21:14:04 : Training AutoML...
2024-09-24 21:14:14 : Best model is lgbm with best model parameters of {'n_estimators': 10, 'num_leaves': 5, 'min_child_samples': 4, 'learning_rate': 0.8571921543782086, 'log_max_bin': 10, 'colsample_bytree': 0.8736741899841435, 'reg_alpha': 0.045055521614150676, 'reg_lambda': 1.5487343522543016}
2024-09-24 21:14:14 : Training AutoML...
2024-09-24 21:14:24 : Best model is lgbm with best model parameters of {'n_estimators': 4, 'num_leaves': 4, 'min_child_samples': 3, 'learning_rate': 0.4526271826745481, 'log_max_bin': 8, 'colsample_bytree': 0.8175779151928938, 'reg_alpha': 0.0009765625, 'reg_lambda': 0.20892183806515865}
2024-09-24 21:14:24 : Training AutoML...
2024-09-24 21:14:34 : Best model is lgbm with best model parameters of {'n_estimators': 24, 'num_leaves': 5, 'min_child_samples': 2, 'learning_rate': 0.16553917456172806, 'log_max_bin': 8, 'colsample_bytree': 0.09534165847954809, 'reg_alpha': 0.06097477862078419, 'reg_lambda': 0.0009765625}
2024-09-24 21:14:34 : Training AutoML...
2024-09-24 21:14:44 : Best model is lgbm with best model parameters of {'n_estimators': 15, 'num_leaves': 5, 'min_child_samples': 2, 'learning_rate': 0.38872795976511465, 'log_max_bin': 7, 'colsample_bytree': 0.7644713278102466, 'reg_alpha': 0.07759140431236793, 'reg_lambda': 0.0009765625}
2024-09-24 21:14:44 : Training AutoML...
2024-09-24 21:14:54 : Best model is lgbm with best model parameters of {'n_estimators': 7, 'num_leaves': 8, 'min_child_samples': 4, 'learning_rate': 0.9346059567885598, 'log_max_bin': 10, 'colsample_bytree': 0.6094519964255998, 'reg_alpha': 0.012059495812453521, 'reg_lambda': 7.339979964592403}
2024-09-24 21:14:54 : Training AutoML...
2024-09-24 21:15:04 : Best model is lgbm with best model parameters of {'n_estimators': 4, 'num_leaves': 4, 'min_child_samples': 20, 'learning_rate': 0.09999999999999995, 'log_max_bin': 8, 'colsample_bytree': 1.0, 'reg_alpha': 0.0009765625, 'reg_lambda': 1.0}
2024-09-24 21:15:04 : Training AutoML...
2024-09-24 21:15:14 : Best model is lgbm with best model parameters of {'n_estimators': 12, 'num_leaves': 4, 'min_child_samples': 2, 'learning_rate': 0.5337794280777547, 'log_max_bin': 4, 'colsample_bytree': 0.17853832068428674, 'reg_alpha': 0.0009819684544183096, 'reg_lambda': 0.08771896280358696}
2024-09-24 21:15:14 : Training AutoML...
2024-09-24 21:15:24 : Best model is lgbm with best model parameters of {'n_estimators': 5, 'num_leaves': 13, 'min_child_samples': 2, 'learning_rate': 0.9050153673020559, 'log_max_bin': 7, 'colsample_bytree': 0.7290288575714409, 'reg_alpha': 0.08233747695576485, 'reg_lambda': 0.18484473777391267}
2024-09-24 21:15:24 : Training AutoML...
2024-09-24 21:15:34 : Best model is lgbm with best model parameters of {'n_estimators': 20, 'num_leaves': 5, 'min_child_samples': 5, 'learning_rate': 0.40688176422506583, 'log_max_bin': 8, 'colsample_bytree': 0.49557577286151167, 'reg_alpha': 0.059826715540903304, 'reg_lambda': 0.0009765625}
2024-09-24 21:15:34 : Training AutoML...
2024-09-24 21:15:44 : Best model is lgbm with best model parameters of {'n_estimators': 13, 'num_leaves': 5, 'min_child_samples': 2, 'learning_rate': 0.47826857447050314, 'log_max_bin': 7, 'colsample_bytree': 0.6476932171895913, 'reg_alpha': 0.02721812430424376, 'reg_lambda': 0.0009765625}
2024-09-24 21:15:44 : Training AutoML...
2024-09-24 21:15:54 : Best model is lgbm with best model parameters of {'n_estimators': 7, 'num_leaves': 9, 'min_child_samples': 2, 'learning_rate': 1.0, 'log_max_bin': 5, 'colsample_bytree': 0.5293718044467112, 'reg_alpha': 0.4134848637908068, 'reg_lambda': 1.7899037923440302}
2024-09-24 21:15:54 : Training AutoML...
2024-09-24 21:16:04 : Best model is lgbm with best model parameters of {'n_estimators': 16, 'num_leaves': 11, 'min_child_samples': 3, 'learning_rate': 0.48941479233171103, 'log_max_bin': 6, 'colsample_bytree': 0.7590590788798283, 'reg_alpha': 0.1689275088229689, 'reg_lambda': 0.11767472345330872}
2024-09-24 21:16:04 : Training AutoML...
2024-09-24 21:16:14 : Best model is lgbm with best model parameters of {'n_estimators': 9, 'num_leaves': 9, 'min_child_samples': 2, 'learning_rate': 1.0, 'log_max_bin': 3, 'colsample_bytree': 0.6071906834084545, 'reg_alpha': 0.0009765625, 'reg_lambda': 1.7759737417667425}
2024-09-24 21:16:14 : Training AutoML...
2024-09-24 21:16:24 : Best model is lgbm with best model parameters of {'n_estimators': 6, 'num_leaves': 5, 'min_child_samples': 2, 'learning_rate': 0.43635519694446395, 'log_max_bin': 10, 'colsample_bytree': 1.0, 'reg_alpha': 0.06219791570362574, 'reg_lambda': 0.0009765625}
2024-09-24 21:16:24 : Training AutoML...
2024-09-24 21:16:34 : Best model is lgbm with best model parameters of {'n_estimators': 6, 'num_leaves': 4, 'min_child_samples': 2, 'learning_rate': 0.5535497865789818, 'log_max_bin': 8, 'colsample_bytree': 1.0, 'reg_alpha': 0.0009765625, 'reg_lambda': 0.15838006664085513}
2024-09-24 21:16:34 : Training AutoML...
2024-09-24 21:16:44 : Best model is lgbm with best model parameters of {'n_estimators': 14, 'num_leaves': 11, 'min_child_samples': 2, 'learning_rate': 0.7732758849730388, 'log_max_bin': 7, 'colsample_bytree': 0.5022550826361638, 'reg_alpha': 0.05702517378903411, 'reg_lambda': 1.753568611251913}
2024-09-24 21:16:44 : Training AutoML...
2024-09-24 21:16:54 : Best model is lgbm with best model parameters of {'n_estimators': 13, 'num_leaves': 8, 'min_child_samples': 2, 'learning_rate': 1.0, 'log_max_bin': 10, 'colsample_bytree': 0.9100031664609475, 'reg_alpha': 0.01705324450041187, 'reg_lambda': 13.244564935289345}
2024-09-24 21:16:54 : Training AutoML...
2024-09-24 21:17:04 : Best model is lgbm with best model parameters of {'n_estimators': 6, 'num_leaves': 5, 'min_child_samples': 2, 'learning_rate': 1.0, 'log_max_bin': 8, 'colsample_bytree': 0.5230615301520156, 'reg_alpha': 0.002711670202936386, 'reg_lambda': 4.5486713208338525}
2024-09-24 21:17:04 : Training AutoML...
2024-09-24 21:17:14 : Best model is lgbm with best model parameters of {'n_estimators': 13, 'num_leaves': 8, 'min_child_samples': 2, 'learning_rate': 0.33421392046699044, 'log_max_bin': 8, 'colsample_bytree': 0.7779086875608411, 'reg_alpha': 0.052609769859006436, 'reg_lambda': 0.11082701194014714}
2024-09-24 21:17:14 : Training AutoML...
2024-09-24 21:17:24 : Best model is lgbm with best model parameters of {'n_estimators': 9, 'num_leaves': 5, 'min_child_samples': 2, 'learning_rate': 0.8943528427558822, 'log_max_bin': 8, 'colsample_bytree': 0.44886287043871437, 'reg_alpha': 0.10058681143507116, 'reg_lambda': 0.05530198191415701}
2024-09-24 21:17:24 : Training AutoML...
2024-09-24 21:17:34 : Best model is lgbm with best model parameters of {'n_estimators': 10, 'num_leaves': 4, 'min_child_samples': 3, 'learning_rate': 1.0, 'log_max_bin': 7, 'colsample_bytree': 0.7500876511043365, 'reg_alpha': 0.015070936475675171, 'reg_lambda': 4.393276343235792}
2024-09-24 21:17:34 : Training AutoML...
2024-09-24 21:17:44 : Best model is lgbm with best model parameters of {'n_estimators': 9, 'num_leaves': 6, 'min_child_samples': 2, 'learning_rate': 0.5256412928723886, 'log_max_bin': 3, 'colsample_bytree': 0.4527081429513771, 'reg_alpha': 0.0009765625, 'reg_lambda': 0.3615431320128289}
2024-09-24 21:17:44 : Training AutoML...
2024-09-24 21:17:54 : Best model is lgbm with best model parameters of {'n_estimators': 7, 'num_leaves': 12, 'min_child_samples': 2, 'learning_rate': 1.0, 'log_max_bin': 3, 'colsample_bytree': 0.9160960930153217, 'reg_alpha': 0.0015946223503420392, 'reg_lambda': 10.821818492068704}
2024-09-24 21:17:54 : Training AutoML...
2024-09-24 21:18:04 : Best model is lgbm with best model parameters of {'n_estimators': 8, 'num_leaves': 6, 'min_child_samples': 2, 'learning_rate': 0.7078474896268241, 'log_max_bin': 3, 'colsample_bytree': 1.0, 'reg_alpha': 0.45791184097577037, 'reg_lambda': 3.6258352815438655}
2024-09-24 21:18:04 : Training AutoML...
2024-09-24 21:18:14 : Best model is lgbm with best model parameters of {'n_estimators': 11, 'num_leaves': 7, 'min_child_samples': 2, 'learning_rate': 0.4976474675540951, 'log_max_bin': 10, 'colsample_bytree': 0.7343521083054644, 'reg_alpha': 0.009142004060822672, 'reg_lambda': 0.2137803668920363}
2024-09-24 21:18:14 : Training AutoML...
2024-09-24 21:18:24 : Best model is lgbm with best model parameters of {'n_estimators': 24, 'num_leaves': 4, 'min_child_samples': 2, 'learning_rate': 0.935838222318515, 'log_max_bin': 6, 'colsample_bytree': 0.5583238173406014, 'reg_alpha': 0.01002075282296741, 'reg_lambda': 10.95638798161344}
2024-09-24 21:18:24 : Training AutoML...
2024-09-24 21:18:34 : Best model is lgbm with best model parameters of {'n_estimators': 5, 'num_leaves': 6, 'min_child_samples': 4, 'learning_rate': 1.0, 'log_max_bin': 9, 'colsample_bytree': 0.5359445694617821, 'reg_alpha': 0.01293007060710423, 'reg_lambda': 1.7821617657499946}
2024-09-24 21:18:34 : Training AutoML...
2024-09-24 21:18:44 : Best model is lgbm with best model parameters of {'n_estimators': 7, 'num_leaves': 4, 'min_child_samples': 2, 'learning_rate': 0.6838568454533844, 'log_max_bin': 8, 'colsample_bytree': 0.4298172382147114, 'reg_alpha': 0.004822916649385623, 'reg_lambda': 0.6246525947739224}
2024-09-24 21:18:44 : Training AutoML...
2024-09-24 21:18:54 : Best model is lgbm with best model parameters of {'n_estimators': 11, 'num_leaves': 16, 'min_child_samples': 4, 'learning_rate': 0.7105321001789935, 'log_max_bin': 6, 'colsample_bytree': 0.6361397370285701, 'reg_alpha': 0.03393538158114423, 'reg_lambda': 0.009254970952528998}
2024-09-24 21:18:54 : Training AutoML...
2024-09-24 21:19:04 : Best model is lgbm with best model parameters of {'n_estimators': 6, 'num_leaves': 4, 'min_child_samples': 3, 'learning_rate': 0.6490652628032392, 'log_max_bin': 10, 'colsample_bytree': 0.7260749083055879, 'reg_alpha': 0.017752941470684333, 'reg_lambda': 0.048632063423479185}
[15]:
model_config = {
'time_budget': 10,
#'max_models': 10, # Maximum number of models to train
#'max_mem_size': '12g', # Maximum memory size for H2O
'estimator_list': ['GBM'], # List of algorithms to use in AutoML
}
mlscdataall_2=nm.mlsc_all(df,'SO2wn','ID',control_pool,'2015-10-23',automl_pkg='h2o', model_config=model_config)
H2O is not running. Starting H2O...
Checking whether there is an H2O instance running at http://localhost:54321.H2O is not running. Starting H2O...
Checking whether there is an H2O instance running at http://localhost:54321.H2O is not running. Starting H2O...
Checking whether there is an H2O instance running at http://localhost:54321.H2O is not running. Starting H2O...
Checking whether there is an H2O instance running at http://localhost:54321.H2O is not running. Starting H2O...
Checking whether there is an H2O instance running at http://localhost:54321.H2O is not running. Starting H2O...
Checking whether there is an H2O instance running at http://localhost:54321.H2O is not running. Starting H2O...
Checking whether there is an H2O instance running at http://localhost:54321. connected.
-------------------------- -------------------------------
H2O_cluster_uptime: 8 hours 57 mins
H2O_cluster_timezone: Europe/London
H2O_data_parsing_timezone: UTC
H2O_cluster_version: 3.46.0.5
H2O_cluster_version_age: 26 days
H2O_cluster_name: H2O_from_python_n94921cs_5qrqdn
H2O_cluster_total_nodes: 1
H2O_cluster_free_memory: 6.827 Gb
H2O_cluster_total_cores: 8
H2O_cluster_allowed_cores: 1
H2O_cluster_status: locked, healthy
H2O_connection_url: http://localhost:54321
H2O_connection_proxy: {"http": null, "https": null}
H2O_internal_security: False
Python_version: 3.12.2 final
-------------------------- -------------------------------
connected.
-------------------------- -------------------------------
H2O_cluster_uptime: 8 hours 57 mins
H2O_cluster_timezone: Europe/London
H2O_data_parsing_timezone: UTC
H2O_cluster_version: 3.46.0.5
H2O_cluster_version_age: 26 days
H2O_cluster_name: H2O_from_python_n94921cs_5qrqdn
H2O_cluster_total_nodes: 1
H2O_cluster_free_memory: 6.827 Gb
H2O_cluster_total_cores: 8
H2O_cluster_allowed_cores: 1
H2O_cluster_status: locked, healthy
H2O_connection_url: http://localhost:54321
H2O_connection_proxy: {"http": null, "https": null}
H2O_internal_security: False
Python_version: 3.12.2 final
-------------------------- -------------------------------
connected.
-------------------------- -------------------------------
H2O_cluster_uptime: 8 hours 57 mins
H2O_cluster_timezone: Europe/London
H2O_data_parsing_timezone: UTC
H2O_cluster_version: 3.46.0.5
H2O_cluster_version_age: 26 days
H2O_cluster_name: H2O_from_python_n94921cs_5qrqdn
H2O_cluster_total_nodes: 1
H2O_cluster_free_memory: 6.827 Gb
H2O_cluster_total_cores: 8
H2O_cluster_allowed_cores: 1
H2O_cluster_status: locked, healthy
H2O_connection_url: http://localhost:54321
H2O_connection_proxy: {"http": null, "https": null}
H2O_internal_security: False
Python_version: 3.12.2 final
-------------------------- -------------------------------
connected.
-------------------------- -------------------------------
H2O_cluster_uptime: 8 hours 57 mins
H2O_cluster_timezone: Europe/London
H2O_data_parsing_timezone: UTC
H2O_cluster_version: 3.46.0.5
H2O_cluster_version_age: 26 days
H2O_cluster_name: H2O_from_python_n94921cs_5qrqdn
H2O_cluster_total_nodes: 1
H2O_cluster_free_memory: 6.827 Gb
H2O_cluster_total_cores: 8
H2O_cluster_allowed_cores: 1
H2O_cluster_status: locked, healthy
H2O_connection_url: http://localhost:54321
H2O_connection_proxy: {"http": null, "https": null}
H2O_internal_security: False
Python_version: 3.12.2 final
-------------------------- -------------------------------
connected.
-------------------------- -------------------------------
H2O_cluster_uptime: 8 hours 57 mins
H2O_cluster_timezone: Europe/London
H2O_data_parsing_timezone: UTC
H2O_cluster_version: 3.46.0.5
H2O_cluster_version_age: 26 days
H2O_cluster_name: H2O_from_python_n94921cs_5qrqdn
H2O_cluster_total_nodes: 1
H2O_cluster_free_memory: 6.827 Gb
H2O_cluster_total_cores: 8
H2O_cluster_allowed_cores: 1
H2O_cluster_status: locked, healthy
H2O_connection_url: http://localhost:54321
H2O_connection_proxy: {"http": null, "https": null}
H2O_internal_security: False
Python_version: 3.12.2 final
-------------------------- -------------------------------
connected.
-------------------------- -------------------------------
H2O_cluster_uptime: 8 hours 57 mins
H2O_cluster_timezone: Europe/London
H2O_data_parsing_timezone: UTC
H2O_cluster_version: 3.46.0.5
H2O_cluster_version_age: 26 days
H2O_cluster_name: H2O_from_python_n94921cs_5qrqdn
H2O_cluster_total_nodes: 1
H2O_cluster_free_memory: 6.827 Gb
H2O_cluster_total_cores: 8
H2O_cluster_allowed_cores: 1
H2O_cluster_status: locked, healthy
H2O_connection_url: http://localhost:54321
H2O_connection_proxy: {"http": null, "https": null}
H2O_internal_security: False
Python_version: 3.12.2 final
-------------------------- -------------------------------
connected.
-------------------------- -------------------------------
H2O_cluster_uptime: 8 hours 57 mins
H2O_cluster_timezone: Europe/London
H2O_data_parsing_timezone: UTC
H2O_cluster_version: 3.46.0.5
H2O_cluster_version_age: 26 days
H2O_cluster_name: H2O_from_python_n94921cs_5qrqdn
H2O_cluster_total_nodes: 1
H2O_cluster_free_memory: 6.827 Gb
H2O_cluster_total_cores: 8
H2O_cluster_allowed_cores: 1
H2O_cluster_status: locked, healthy
H2O_connection_url: http://localhost:54321
H2O_connection_proxy: {"http": null, "https": null}
H2O_internal_security: False
Python_version: 3.12.2 final
-------------------------- -------------------------------
2024-09-24 21:19:08: Training AutoML...
2024-09-24 21:19:08: Training AutoML...
2024-09-24 21:19:08: Training AutoML...
2024-09-24 21:19:08: Training AutoML...
2024-09-24 21:19:08: Training AutoML...
2024-09-24 21:19:08: Training AutoML...
2024-09-24 21:19:08: Training AutoML...
21:19:08.260: _min_rows param, The dataset size is too small to split for min_rows=100.0: must have at least 200.0 (weighted) rows, but have only 25.0.
21:19:08.259: _min_rows param, The dataset size is too small to split for min_rows=100.0: must have at least 200.0 (weighted) rows, but have only 25.0.
21:19:08.260: _min_rows param, The dataset size is too small to split for min_rows=100.0: must have at least 200.0 (weighted) rows, but have only 25.0.
21:19:08.259: _min_rows param, The dataset size is too small to split for min_rows=100.0: must have at least 200.0 (weighted) rows, but have only 25.0.
21:19:08.259: _min_rows param, The dataset size is too small to split for min_rows=100.0: must have at least 200.0 (weighted) rows, but have only 25.0.
21:19:08.263: _min_rows param, The dataset size is too small to split for min_rows=100.0: must have at least 200.0 (weighted) rows, but have only 25.0.
21:19:08.263: _min_rows param, The dataset size is too small to split for min_rows=100.0: must have at least 200.0 (weighted) rows, but have only 25.0.
2024-09-24 21:19:19: Best model obtained! - GBM_3_AutoML_86_20240924_211908
2024-09-24 21:19:19: Best model obtained! - GBM_3_AutoML_87_20240924_211908
2024-09-24 21:19:19: Best model obtained! - GBM_2_AutoML_91_20240924_211908
2024-09-24 21:19:19: Best model obtained! - GBM_3_AutoML_90_20240924_211908
2024-09-24 21:19:19: Best model obtained! - GBM_3_AutoML_85_20240924_211908
2024-09-24 21:19:19: Best model obtained! - GBM_3_AutoML_88_20240924_211908
2024-09-24 21:19:19: Best model obtained! - GBM_2_AutoML_89_20240924_211908
2024-09-24 21:19:19: Training AutoML...
21:19:19.987: _min_rows param, The dataset size is too small to split for min_rows=100.0: must have at least 200.0 (weighted) rows, but have only 25.0.
2024-09-24 21:19:20: Training AutoML...
21:19:21.723: _min_rows param, The dataset size is too small to split for min_rows=100.0: must have at least 200.0 (weighted) rows, but have only 25.0.
2024-09-24 21:19:31: Training AutoML...
2024-09-24 21:19:31: Training AutoML...
2024-09-24 21:19:31: Training AutoML...
21:19:32.77: _min_rows param, The dataset size is too small to split for min_rows=100.0: must have at least 200.0 (weighted) rows, but have only 25.0.
21:19:32.735: _min_rows param, The dataset size is too small to split for min_rows=100.0: must have at least 200.0 (weighted) rows, but have only 25.0.
21:19:32.735: _min_rows param, The dataset size is too small to split for min_rows=100.0: must have at least 200.0 (weighted) rows, but have only 25.0.
2024-09-24 21:19:43: Training AutoML...
21:19:43.490: _min_rows param, The dataset size is too small to split for min_rows=100.0: must have at least 200.0 (weighted) rows, but have only 25.0.
2024-09-24 21:19:43: Best model obtained! - GBM_5_AutoML_93_20240924_211920
2024-09-24 21:19:44: Training AutoML...
2024-09-24 21:19:43: Best model obtained! - GBM_5_AutoML_96_20240924_211931
21:19:45.241: _min_rows param, The dataset size is too small to split for min_rows=100.0: must have at least 200.0 (weighted) rows, but have only 25.0.
2024-09-24 21:19:55: Training AutoML...
21:19:55.541: _min_rows param, The dataset size is too small to split for min_rows=100.0: must have at least 200.0 (weighted) rows, but have only 25.0.
2024-09-24 21:19:55: Training AutoML...
21:19:57.263: _min_rows param, The dataset size is too small to split for min_rows=100.0: must have at least 200.0 (weighted) rows, but have only 25.0.
2024-09-24 21:19:55: Best model obtained! - GBM_3_AutoML_94_20240924_211931
2024-09-24 21:19:55: Best model obtained! - GBM_5_AutoML_95_20240924_211931
2024-09-24 21:19:55: Best model obtained! - GBM_grid_1_AutoML_92_20240924_211919_model_2
2024-09-24 21:20:07: Best model obtained! - GBM_2_AutoML_97_20240924_211943
2024-09-24 21:20:07: Best model obtained! - GBM_grid_1_AutoML_98_20240924_211944_model_2
2024-09-24 21:20:08: Training AutoML...
21:20:08.104: _min_rows param, The dataset size is too small to split for min_rows=100.0: must have at least 200.0 (weighted) rows, but have only 25.0.
2024-09-24 21:20:08: Training AutoML...
21:20:09.948: _min_rows param, The dataset size is too small to split for min_rows=100.0: must have at least 200.0 (weighted) rows, but have only 25.0.
2024-09-24 21:20:18: Training AutoML...
2024-09-24 21:20:18: Training AutoML...
21:20:20.473: _min_rows param, The dataset size is too small to split for min_rows=100.0: must have at least 200.0 (weighted) rows, but have only 25.0.
21:20:21.551: _min_rows param, The dataset size is too small to split for min_rows=100.0: must have at least 200.0 (weighted) rows, but have only 25.0.
2024-09-24 21:20:32: Training AutoML...
21:20:32.395: _min_rows param, The dataset size is too small to split for min_rows=100.0: must have at least 200.0 (weighted) rows, but have only 25.0.
2024-09-24 21:20:32: Best model obtained! - GBM_5_AutoML_99_20240924_211955
2024-09-24 21:20:32: Best model obtained! - GBM_5_AutoML_100_20240924_211955
2024-09-24 21:20:36: Best model obtained! - GBM_5_AutoML_102_20240924_212008
2024-09-24 21:20:40: Best model obtained! - GBM_5_AutoML_103_20240924_212018
2024-09-24 21:20:41: Best model obtained! - GBM_3_AutoML_101_20240924_212008
2024-09-24 21:20:41: Best model obtained! - GBM_5_AutoML_104_20240924_212018
2024-09-24 21:20:42: Training AutoML...
21:20:42.15: _min_rows param, The dataset size is too small to split for min_rows=100.0: must have at least 200.0 (weighted) rows, but have only 25.0.
2024-09-24 21:20:43: Training AutoML...
21:20:49.257: _min_rows param, The dataset size is too small to split for min_rows=100.0: must have at least 200.0 (weighted) rows, but have only 25.0.
2024-09-24 21:20:51: Training AutoML...
2024-09-24 21:20:51: Training AutoML...
2024-09-24 21:20:51: Training AutoML...
2024-09-24 21:20:51: Training AutoML...
21:20:53.162: _min_rows param, The dataset size is too small to split for min_rows=100.0: must have at least 200.0 (weighted) rows, but have only 25.0.
21:20:53.162: _min_rows param, The dataset size is too small to split for min_rows=100.0: must have at least 200.0 (weighted) rows, but have only 25.0.
21:20:59.570: _min_rows param, The dataset size is too small to split for min_rows=100.0: must have at least 200.0 (weighted) rows, but have only 25.0.
2024-09-24 21:21:08: Best model obtained! - GBM_grid_1_AutoML_105_20240924_212032_model_5
2024-09-24 21:21:14: Best model obtained! - GBM_grid_1_AutoML_106_20240924_212042_model_4
2024-09-24 21:21:14: Best model obtained! - GBM_5_AutoML_109_20240924_212051
2024-09-24 21:21:14: Best model obtained! - GBM_5_AutoML_107_20240924_212043
2024-09-24 21:21:14: Best model obtained! - GBM_2_AutoML_111_20240924_212051
2024-09-24 21:21:14: Best model obtained! - GBM_5_AutoML_110_20240924_212051
21:21:03.828: _min_rows param, The dataset size is too small to split for min_rows=100.0: must have at least 200.0 (weighted) rows, but have only 25.0.
2024-09-24 21:21:15: Best model obtained! - GBM_grid_1_AutoML_108_20240924_212051_model_2
2024-09-24 21:21:15: Training AutoML...
21:21:15.484: _min_rows param, The dataset size is too small to split for min_rows=100.0: must have at least 200.0 (weighted) rows, but have only 25.0.
2024-09-24 21:21:15: Training AutoML...
2024-09-24 21:21:15: Training AutoML...
2024-09-24 21:21:15: Training AutoML...
21:21:16.728: _min_rows param, The dataset size is too small to split for min_rows=100.0: must have at least 200.0 (weighted) rows, but have only 25.0.
21:21:26.158: _min_rows param, The dataset size is too small to split for min_rows=100.0: must have at least 200.0 (weighted) rows, but have only 25.0.
21:21:26.158: _min_rows param, The dataset size is too small to split for min_rows=100.0: must have at least 200.0 (weighted) rows, but have only 25.0.
2024-09-24 21:21:28: Training AutoML...
2024-09-24 21:21:28: Training AutoML...
21:21:37.71: _min_rows param, The dataset size is too small to split for min_rows=100.0: must have at least 200.0 (weighted) rows, but have only 25.0.
21:21:37.71: _min_rows param, The dataset size is too small to split for min_rows=100.0: must have at least 200.0 (weighted) rows, but have only 25.0.
2024-09-24 21:21:37: Training AutoML...
21:21:47.951: _min_rows param, The dataset size is too small to split for min_rows=100.0: must have at least 200.0 (weighted) rows, but have only 25.0.
2024-09-24 21:21:57: Best model obtained! - GBM_grid_1_AutoML_114_20240924_212115_model_2
2024-09-24 21:21:58: Best model obtained! - GBM_5_AutoML_112_20240924_212115
2024-09-24 21:21:58: Best model obtained! - GBM_5_AutoML_113_20240924_212115
2024-09-24 21:21:58: Best model obtained! - GBM_5_AutoML_116_20240924_212128
2024-09-24 21:21:58: Best model obtained! - GBM_5_AutoML_115_20240924_212115
2024-09-24 21:21:58: Best model obtained! - GBM_5_AutoML_117_20240924_212128
2024-09-24 21:21:58: Best model obtained! - GBM_grid_1_AutoML_118_20240924_212137_model_4
2024-09-24 21:21:58: Training AutoML...
21:21:58.779: _min_rows param, The dataset size is too small to split for min_rows=100.0: must have at least 200.0 (weighted) rows, but have only 25.0.
2024-09-24 21:21:58: Training AutoML...
2024-09-24 21:21:58: Training AutoML...
2024-09-24 21:21:58: Training AutoML...
21:22:00.851: _min_rows param, The dataset size is too small to split for min_rows=100.0: must have at least 200.0 (weighted) rows, but have only 25.0.
21:22:05.148: _min_rows param, The dataset size is too small to split for min_rows=100.0: must have at least 200.0 (weighted) rows, but have only 25.0.
21:22:05.148: _min_rows param, The dataset size is too small to split for min_rows=100.0: must have at least 200.0 (weighted) rows, but have only 25.0.
2024-09-24 21:22:16: Best model obtained! - GBM_grid_1_AutoML_122_20240924_212158_model_2
2024-09-24 21:22:16: Best model obtained! - GBM_5_AutoML_120_20240924_212158
2024-09-24 21:22:16: Best model obtained! - GBM_5_AutoML_119_20240924_212158
2024-09-24 21:22:16: Best model obtained! - GBM_5_AutoML_121_20240924_212158
[16]:
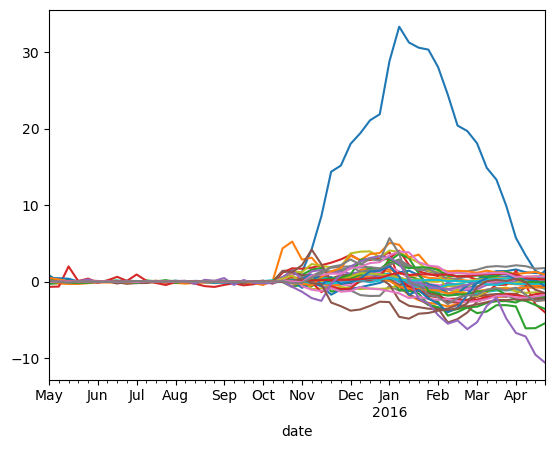
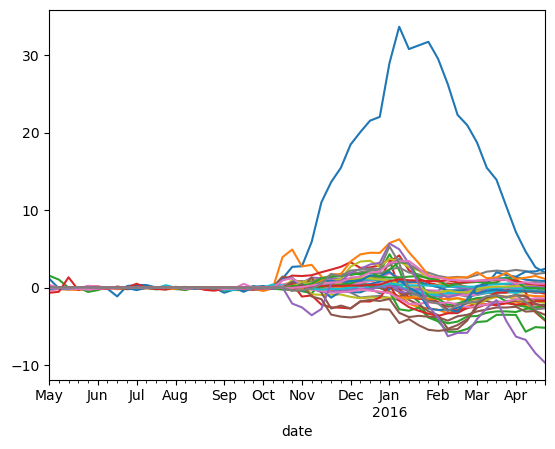
fig,ax=plt.subplots()
for i,city in enumerate(list(mlscdataall_1['ID'].unique())):
mlscdataall_1[mlscdataall_1['ID']==city]['effects'].plot(ax=ax)
[17]:
fig,ax=plt.subplots()
for i,city in enumerate(list(mlscdataall_2['ID'].unique())):
mlscdataall_2[mlscdataall_2['ID']==city]['effects'].plot(ax=ax)
Closing connection _sid_8dbb at exit
H2O session _sid_8dbb closed.
Closing connection _sid_8531 at exit
H2O session _sid_8531 closed.
Closing connection _sid_ac4f at exit
H2O session _sid_ac4f closed.
Closing connection _sid_b025 at exit
H2O session _sid_b025 closed.
Closing connection _sid_8597 at exit
H2O session _sid_8597 closed.
Closing connection _sid_90c2 at exit
H2O session _sid_90c2 closed.
Closing connection _sid_b4d2 at exit
H2O session _sid_b4d2 closed.
[ ]: